Dedicated to Mar García in memoriam
“Horror Vacui” is an interactive algorithmic piece for two moving singers, live electronics, sensors, a real-time notation and score generation system, and IoT devices.
This work was premiered at the Audio Mostly 22 conference in Sankt Pölten Austria. Claire E. Craig and Reinhild Buchmayer sang the work. Two weeks later it was accepted and programmed at the Convergence Conference in Leicester. This time, the work was sung by Charis Buckingham and Francesca Burbela.
Claire E. Craig and Reinhild Buchmayer singing “Horror Vacui” at Sankt Pölten , Austria
The work is real-time algorithmically composed through the movement of the sopranos on stage.
The movement of the singers is measured by a sensor and sent to the computer via WIFI. The computer returns the notes to be sung by a real-time notation system. This work is a circular self-referential system. The sopranos react to the notes by changing the way they move and the computer creates the score of the sopranos reacting to the movement of the sopranos. “Horror Vacui” is a Latin-derived term used to explain our relationship with the void. “Horror vacui” refers to the fact that the singers do not know what they will sing in advance, and that the self-referential system is not based on anything a-priori.
Charis Buckingham and Francesca Burbela singing “Horror Vacui” at Leicester, UK Convergence Festival 2022
“Horror Vacui” is an experiment about forms of creativity based on collaborative intelligence through the gamification of the creative process by making a cooperative musical game between the two sopranos. The sopranos and the computer collaborate to create the work interactively out of the sopranos´ movement on stage. The roles of performers composers and scenic space are interchanged.
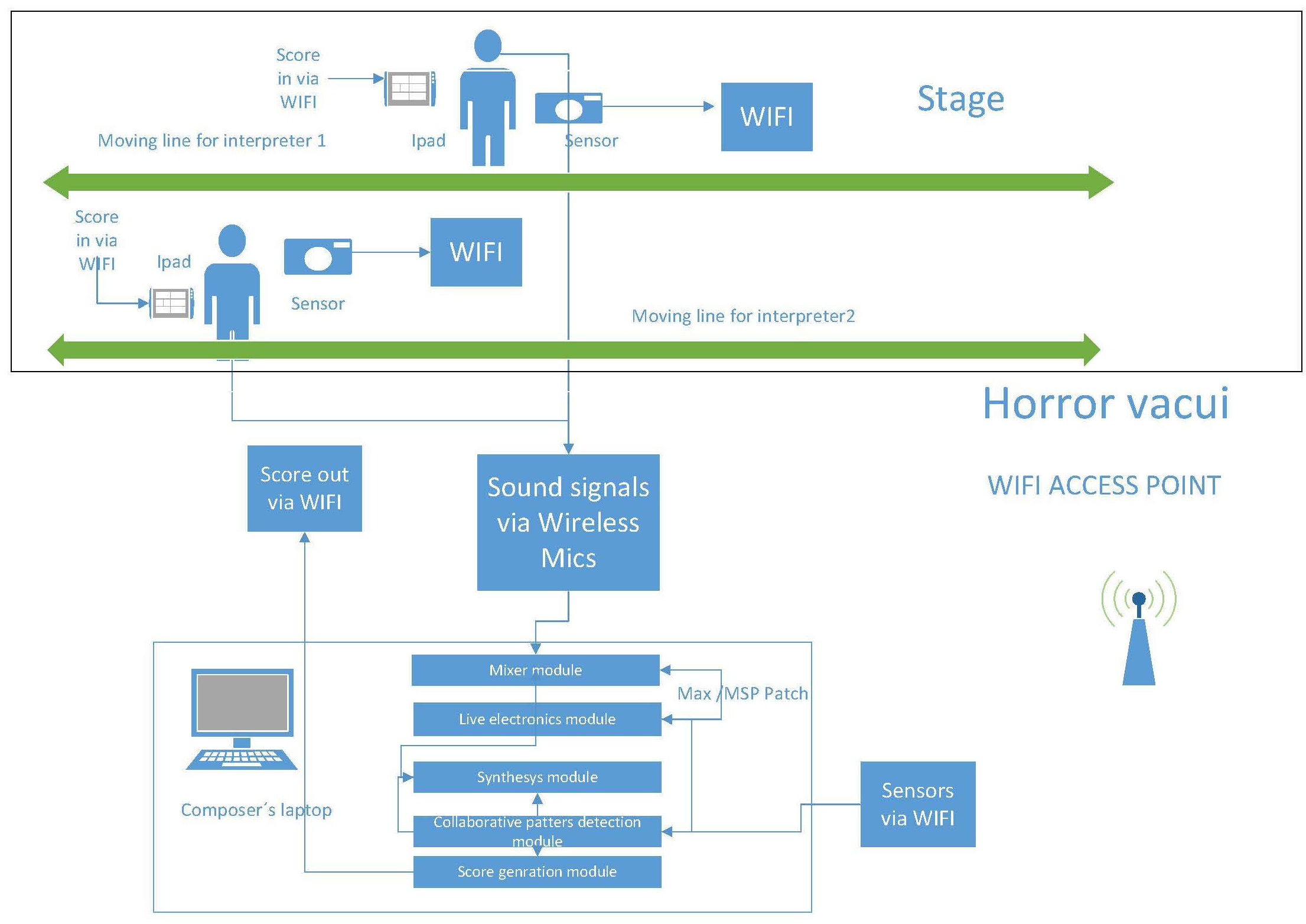
Schema of the work.
The resulting work is the mix of these three sound sources: the two voices, its real-time electronic modification, and the real-time synthesis generation. The sensors will send their signals via WIFI to Max/Msp and convert them into MIDI data for the synthesis engine and the score for the two voices. The score generator scales the data to accommodate the singers’ span. They will see it on a portable device, like an iPad or mobile phone. The singers will receive specific instructions for handling the notes and moving in the sensor line. The work can last between 10 and 15 minutes.

Sensor belts, Mobiles, and Wireless microphones ready for the Salzburg rehearsal

Complete singer´s kit. The mobile with the App, sensor belt, Arduino belt, and wireless mic for the Sankt Pölten performance.

Complete equipment for the performance.
In this video, you can see the mobiles receiving the notes.
References
- [1] Egido, Fernando. Artificial Computational Creativity based on Collaborative Intelligence (2020). Lectured in the Artificial Intelligence Music Creativity 2021 Graz.
- [2] Egido, Fernando. Using a Distribution Probability Follower in MAS Works (2018) Paper lectured at the Korea Electro-Acoustic Music Society’s Annual Conference 2019.
Similar works
- Collaborametrum (2018) https://busevin.art/collaborametrum/
- Transcognition (2018) https://busevin.art/transcognition/
- Public stage ( 2023) https://busevin.wordpress.com/public-stage-2023/
- Collaboration as an Act of Creativity (2022) https://busevin.art/collaboration-as-an-act-of-creativity/
